
在D3D中,为什么采用顶点缓存来存储顶点而不采用数组()。A、因为对数组的使用比较麻烦B、因为数组所占用的存储空间较大C、因为顶点缓存可以被存放在显存中D、因为顶点缓存可以被放置在系统主存储区中
题目
在D3D中,为什么采用顶点缓存来存储顶点而不采用数组()。
- A、因为对数组的使用比较麻烦
- B、因为数组所占用的存储空间较大
- C、因为顶点缓存可以被存放在显存中
- D、因为顶点缓存可以被放置在系统主存储区中
相似考题
参考答案和解析
更多“在D3D中,为什么采用顶点缓存来存储顶点而不采用数组()。A、因为对数组的使用比较麻烦B、因为数组所占用的存储空间较大C、因为顶点缓存可以被存放在显存中D、因为顶点缓存可以被放置在系统主存储区中”相关问题
-
第1题:
下面关于图的存储的叙述中正确的是()。
A.用邻接表法存储图,占用的存储空间大小只与图中边数有关,而与顶点个数无关
B.用邻接表法存储图,占用的存储空间大小与图中边数和顶点个数都有关
C.用邻接矩阵法存储图,占用的存储空间大小与图中顶点个数和边数无关
D.用邻接矩阵存储图,占用的存储空间大小只与图中边数有关,而与顶点个数无关
正确答案:B
-
第2题:
图的深度优先遍历算法中需要设置一个标志数组,以便区分图中的每个顶点是否被访问过。()答案:对解析:深度优先遍历算法需设置一个数组,用来标志顶点是否被访问过。 -
第3题:
在索引缓存中定位顶点也就是在顶点缓存中定位顶点。
正确答案:正确 -
第4题:
顶点缓存中的顶点可以包含顶点坐标、颜色、法线方向、纹理坐标等属性,具体包含哪些属性,可以使用灵活顶点格式(Flexible Vertex Format,FVF)进行描述;请解释下面部分FVF描述符: D3DFVF_DIFFUSE, D3DFVF_NORMAL,D3DFVF_XYZ,D3DFVF_XYZRHW,D3DFVF_SPECULAR
正确答案: D3DFVF_DIFFUSE://顶点数据中包含漫反射颜色值;
D3DFVF_NORMAL:顶点数据中包含法线向量,不能和D3DFVF_XYZRHW同时使用;
D3DFVF_XYZ:顶点数据中包含未经坐标变换的顶点坐标,不能与D3DFVF_XYZRHW同时使用;
D3DFVF_XYZRHW:顶点数据中包含经过坐标变换的顶点坐标,不能与D3DFVF_XYZ和D3DFVF_NORMAL同时使用;
D3DFVF_PSIZE://顶点信息指明绘制点的大小;
D3DFVF_SPECULAR:顶点数据中镜面反射效果下的颜色值。 -
第5题:
在Java语言中,对于数组的创建和数组占用空间的回收,下列说法中不正确的是():
- A、数组可以通过使用new操作符来获取所需要的存储空间。
- B、数组声明的同时,必须使用直接初始化的方式完成创建。
- C、数组使用完成后,所占用的存储空间的释放是由垃圾收集器自动回收的。
- D、利用new操作符方式创建的数组元素会自动被初始化为一个默认值。
正确答案:B -
第6题:
对于一个具有n个顶点和e条边的有向图和无向图,若采用边集数组表示,则存于数组中的边数分别为()和()条。
正确答案:e;e -
第7题:
假定用一维数组d[n]存储一个AOV网中用于拓扑排序的顶点入度,则值为0的元素被链接成为一个()。
正确答案:链栈 -
第8题:
混合过程中欲使截面的顶点数相同,可以()。
- A、打断截面
- B、混合顶点
- C、在截面边线上再次绘制图线
- D、使用一点作为截面
- E、删除顶点多的截面的顶点
正确答案:A,B -
第9题:
判断题在索引缓存中定位顶点也就是在顶点缓存中定位顶点。A对
B错
正确答案: 对解析: 暂无解析 -
第10题:
单选题如果要对Mesh进行优化,需要知道Mesh的三角形的邻接信息情况,这些信息存储在()中。A邻接矩阵
B邻接缓存
C深度缓存
D邻接数组
正确答案: A解析: 暂无解析 -
第11题:
问答题顶点缓存中的顶点可以包含顶点坐标、颜色、法线方向、纹理坐标等属性,具体包含哪些属性,可以使用灵活顶点格式(Flexible Vertex Format,FVF)进行描述;请解释下面部分FVF描述符: D3DFVF_DIFFUSE, D3DFVF_NORMAL,D3DFVF_XYZ,D3DFVF_XYZRHW,D3DFVF_SPECULAR正确答案: D3DFVF_DIFFUSE://顶点数据中包含漫反射颜色值;
D3DFVF_NORMAL:顶点数据中包含法线向量,不能和D3DFVF_XYZRHW同时使用;
D3DFVF_XYZ:顶点数据中包含未经坐标变换的顶点坐标,不能与D3DFVF_XYZRHW同时使用;
D3DFVF_XYZRHW:顶点数据中包含经过坐标变换的顶点坐标,不能与D3DFVF_XYZ和D3DFVF_NORMAL同时使用;
D3DFVF_PSIZE://顶点信息指明绘制点的大小;
D3DFVF_SPECULAR:顶点数据中镜面反射效果下的颜色值。解析: 暂无解析 -
第12题:
填空题假定用一维数组d[n]存储一个AOV网中用于拓扑排序的顶点入度,则值为0的元素被链接成为一个()。正确答案: 链栈解析: 暂无解析 -
第13题:
图的深度优先遍历算法中需要设置一个标志数组,以便区分图中的每个顶点是否被访问过。
此题为判断题(对,错)。
正确答案:√
-
第14题:
对于具有n个顶点、6条边的图()。A.采用邻接矩阵表示图时,查找所有顶点的邻接顶点的时间复杂度为O(n2)
B.进行广度优先遍历运算所消耗的时间与采用哪一种存储结构无关
C.采用邻接表表示图时,查找所有顶点的邻接顶点的时间复杂度为O(n*e)
D.进行深度优先遍历运算所消耗的时间与采用哪一种存储结构无关答案:A解析: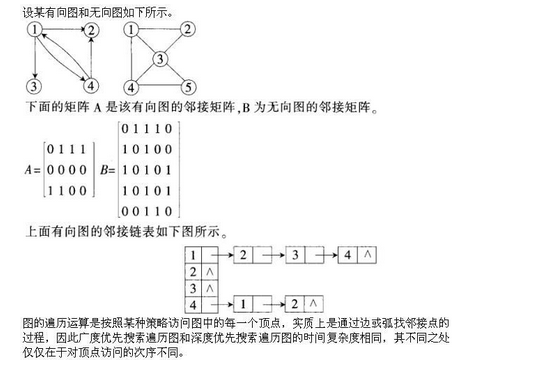
-
第15题:
如果要对Mesh进行优化,需要知道Mesh的三角形的邻接信息情况,这些信息存储在()中。
- A、邻接矩阵
- B、邻接缓存
- C、深度缓存
- D、邻接数组
正确答案:D -
第16题:
在对缓存区填充数据库,可以无限填充数据,因为操作系统会自动增大缓存区大小。
正确答案:错误 -
第17题:
一维数组通常采用顺序存储结构,这是因为()。
- A、一维数组是一种线性数据结构
- B、一维数组是一种动态数据结构
- C、一旦建立了数组,则数组中的数据元素之间的关系不再变动
- D、一维数组只能采用顺序存储结构
正确答案:C -
第18题:
将数组称为随机存取结构是因为()
- A、数组元素是随机的
- B、对数组任一元素的存取时间是相等的
- C、随时可以对数组进行访问
- D、数组的存储结构是不定
正确答案:B -
第19题:
动态数组是指计算机在执行过程中才给数组开辟存储空间的数组。
正确答案:正确 -
第20题:
单选题一维数组通常采用顺序存储结构,这是因为()。A一维数组是一种线性数据结构
B一维数组是一种动态数据结构
C一旦建立了数组,则数组中的数据元素之间的关系不再变动
D一维数组只能采用顺序存储结构
正确答案: B解析: 暂无解析 -
第21题:
判断题动态数组是指计算机在执行过程中才给数组开辟存储空间的数组。A对
B错
正确答案: 错解析: 暂无解析 -
第22题:
填空题对于一个具有n个顶点和e条边的有向图和无向图,若采用边集数组表示,则存于数组中的边数分别为()和()条。正确答案: e,e解析: 暂无解析 -
第23题:
单选题在Java语言中,对于数组的创建和数组占用空间的回收,下列说法中不正确的是():A数组可以通过使用new操作符来获取所需要的存储空间。
B数组声明的同时,必须使用直接初始化的方式完成创建。
C数组使用完成后,所占用的存储空间的释放是由垃圾收集器自动回收的。
D利用new操作符方式创建的数组元素会自动被初始化为一个默认值。
正确答案: D解析: 暂无解析